
沒有先進光刻機也能突圍高端芯片,華爲發表的「韜(τ)定律」是什麼?

作者:何庭波,半導體產業縱橫
6年研發,華爲完成381款芯片量產落地。
在ISCAS 2026,華爲何庭波發表題爲「半導體新路徑探索與實踐」的主旨演講,發表了指導半導體產業發展的新原則——韜(τ)定律,旨在破解摩爾定律面臨的物理和經濟困局。
演講報告詳細內容將以「A Time Scaling Theory for Multi-Layer Electronic Systems」爲題發表在SCIENCE CHINA Information Sciences上。
六十年來,摩爾定律的幾何尺寸縮減推動着半導體產業不斷髮展。如今這套行業發展範式已然失效:單純縮小芯片尺寸帶來的技術紅利日漸枯竭,單顆尖端芯片的設計成本突破十億美元,先進製程下單個晶體管的成本也不再下降。本文提出時間縮放準則(τ縮放)作爲全新發展範式,不再以晶體管面積作爲技術進步的核心衡量標準,轉而將時間本身定爲核心指標。該準則以統一特徵時間常數τ爲優化目標,覆蓋從晶體管開關動作到數據中心業務負載,跨度達12個數量級。
文中展示兩項量產級技術實證案例:在移動端系統級芯片上,邏輯摺疊技術將數字電路、模擬電路與存儲電路分層排佈於垂直堆疊的有源層,固定制程下晶體管密度階段性提升55%,能效提升41%。在人工智能系統領域,融合存儲語義統一總線架構、封裝近距高速光電互聯接口與立體堆疊摺疊技術的協同設計體系,預計到2035年可實現硬件集成度百倍以上增長。從技術方法論層面而言,τ縮放是繼登納德縮放定律之後,首個能夠貫穿整個計算架構、建立統一優化目標的技術準則。
自20世紀60年代中期起,半導體產業始終以納米尺寸衡量技術迭代水平。行業曾保持每18個月晶體管尺寸縮小、運行頻率提升、單邏輯門成本下降的發展節奏。摩爾定律既是客觀產業規律,也構建起支撐整套計算體系發展的行業共識。
現如今這一共識已不復存在。邁入7納米及以下製程後,幾何尺寸縮減無法再復刻過往的技術收益。光刻工藝逼近圖形制備物理極限,極紫外光刻設備折舊成本佔據晶圓製造成本大頭,單晶體管成本增長停滯甚至出現反彈。對於無法獲取頂尖光刻設備的企業,發展受限問題顯現更早,產業承壓也更爲嚴峻。
產業核心發展命題由此發生轉變,不再是探究晶體管還能做多小,而是明確優化對象與發展目標。
過去六年,華爲半導體團隊基於手機SoC、人工智能加速器、系統互聯架構及封裝技術,開展全芯片級技術研究。研究得出結論:技術突破並非依賴全新制程節點或晶體管架構,而是要重構核心優化方向。本文認爲,未來十年電子系統的演進,將告別幾何尺寸縮放模式,邁入時間縮放新階段。從皮秒級晶體管開關響應,到秒級數據中心任務處理,計算體系各層級均圍繞特徵時間常數τ實現系統性縮減。
本文結合2020年5月至2026年5月量產落地的381款芯片研發經驗,從科學方法與產業路線兩大維度,闡釋τ縮放技術體系。
半導體產業長期以來的核心任務,就是持續縮小晶體管體積。1965年戈登・摩爾提出晶體管密度約每兩年翻倍的論斷,十年後羅伯特・登納德提出縮放理論,證實電壓與尺寸等比例縮減可維持穩定電場強度。
近五十年間,幾何縮放結合登納德縮放,讓芯片單位功耗性能、單位成本性能實現指數級提升。
這一發展範式分兩個階段走向崩塌:2005年前後:登納德縮放率先失效,電壓不再隨特徵尺寸等比例下降,芯片暗硅時代開啓;7納米節點之後:依靠鰭式場效應晶體管(FinFET)、環繞柵極(GAA)架構延續的幾何縮放紅利徹底見頂。核心成因已形成行業共識:速度飽和效應使本徵延遲與溝道長度從二次相關變爲線性相關;局部互連線寄生電阻、電容逐漸主導標準單元延遲預算;掩模成本、EUV折舊、設計規則複雜度飆升,2納米節點單顆頂尖芯片設計預算突破10億美元。
經濟層面同樣無可迴避:先進製程單晶體管成本停滯、頂尖節點成本甚至上漲;維持五十年的每代晶體管更多、成本更低的行業邏輯徹底瓦解。
對華爲半導體而言,先進光刻設備受限疊加幾何路線見頂,倒逼我們直面全行業終將面臨的根本問題:必須跳出工藝節點依賴,重構底層技術演進邏輯。
從用戶實際體驗來看,摩爾定律的核心從來不在於尺寸大小。晶體管體積變小,開關響應速度隨之加快;互聯線路排布更緊湊,信號傳輸距離縮短;集成度不斷提升,數據交互邊界減少。
歷代芯片迭代,本質都是不斷壓縮運行耗時:器件層面時間跨度爲皮秒至納秒,芯片層面爲納秒至微秒,系統層面爲微秒至秒。空間尺寸縮減,只是壓縮運行時間的手段。
基於這一核心邏輯,產業優化思路迎來全新變革,將時間確立爲核心衡量指標。晶體管、電路、芯片、系統各層級均可定義特徵時間常數τ,並將縮減τ定爲統一優化目標。幾何尺寸縮放僅成爲降低時間損耗的手段之一。
本文將這一準則定義爲τ時間縮放,作爲接替摩爾幾何縮放、引領半導體產業演進的全新底層理論。特徵時間常數滿足層級函數關係:
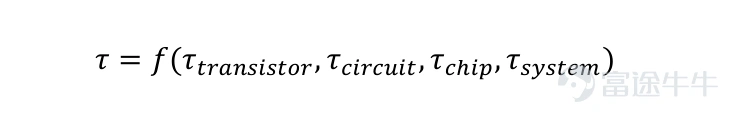
各層級時間常數由下層基礎耗時,疊加本級架構、通信交互損耗共同構成。τ的時間跨度覆蓋皮秒至秒,空間跨度涵蓋納米至千米。各層級縮減τ的技術路徑各有側重:
晶體管層級:優化固有開關延遲,依託載流子遷移率提升、應力工藝、高介電常數金屬柵極、環繞柵極架構改良,同時削減局部互聯寄生阻容參數;
電路層級:優化信號傳輸阻容延遲,採用低阻導線、低介電介質材料,依託垂直集成縮短佈線長度;
芯片層級:降低運算與存儲訪問延遲,通過架構設計、流水線配置、存儲層級與片上互聯網絡實現優化;
系統層級:壓縮端到端數據傳輸與同步耗時,優化互聯拓撲、通信協議與組網架構。

由此可得出芯片代際迭代規律:下一代時間常數等於當前時間常數除以縮放係數。縮放係數依據應用場景區分:功耗受限的移動端設備年均縮放係數約1.3倍;高可靠性自動駕駛系統約1.5倍;算力直接決定經濟效益的人工智能業務可達10倍。
τ指標能夠統籌全計算架構,頻率、延遲、帶寬、吞吐量等性能參數,本質均由對應層級的τ決定。工藝研發、電路設計、系統架構人員可基於統一指標協同優化,各層級獨立優化、事後覈算時序損耗的發展模式就此終結。
τ縮放技術首次規模化落地測試應用於移動端場景。智能手機SoC較爲特殊,單顆芯片即可構成整套設備系統。設備無法多路插槽並行運算,也不存在數千節點互聯架構來抵消鏈路延遲。整機所有性能輸出均依託單一裸片實現,功耗僅數瓦,同時還要受機身形態帶來的散熱條件約束。
2020年後,先進製程獲取受限,行業面臨核心問題:製程工藝不再迭代的前提下,如何持續實現單顆芯片代際性能升級?
邏輯摺疊技術就此應運而生。
定義:邏輯摺疊是遵循時間縮放原理,將數字電路、模擬電路與存儲電路拆分排布至縱向堆疊的多層有源芯片層,統籌優化芯片性能、功耗與面積的設計方案。
數字電路分爲組合邏輯與時序邏輯兩類:組合邏輯指寄存器之間的布爾運算電路,時序邏輯則是負責存儲狀態的觸發器。數字系統性能上限由相鄰觸發器間的關鍵路徑延遲決定,而延遲主要受線路寄生阻容參數與路徑門電路數量影響。傳統設計將門電路平鋪在同一平面,佈線依託上層金屬層完成;佈線長度越長,寄生阻容損耗越高,關鍵路徑運行速度也就越慢。
邏輯摺疊打破平面設計思路,把關鍵路徑的門電路拆分排布至兩層乃至更多縱向堆疊的有源芯片層,通過超細間距混合鍵合技術完成層間互聯。
從電路設計角度來看,多層芯片可視作一體化完整架構,器件跨層分佈,效果等同於新增金屬佈線層。信號走線長度大幅縮減,寄生阻容損耗顯著下降,時鐘偏差得到優化,同一製程工藝下芯片能夠實現更高主頻運行。
想要充分發揮邏輯摺疊的性能優勢,需將混合鍵合間距與頂層金屬間距的比值控制在較低水平,實操中建議低於3,比值越小綜合表現越好。當前頂層金屬間距約720納米,對應混合鍵合間距需控制在2微米以內;理想狀態下二者比值趨近於1,可徹底消除鍵合界面的佈線冗餘損耗。
實現該鍵合間距,同時滿足小於0.5微米的套刻精度、孔徑與隔離區小於1.5微米、間距小於6微米的硅通孔規格,以及依託智能冗餘技術趨近滿良率的生產要求,產業鏈上下游歷經多年工藝研發才得以達成。
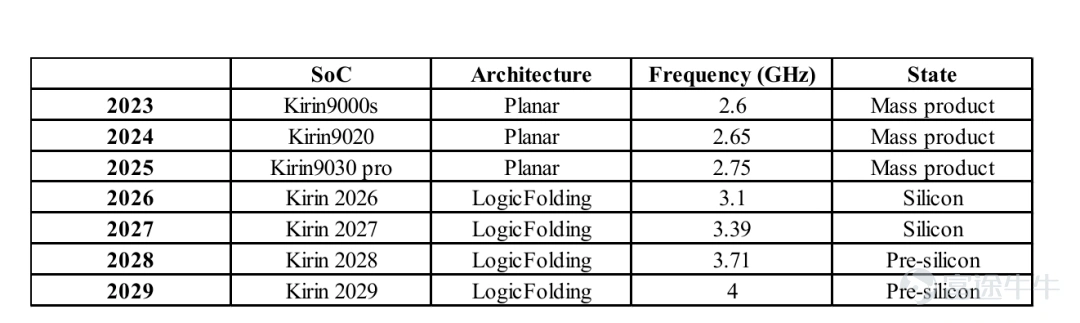
2026款麒麟芯片實測取得多項實質成效:
晶體管密度在單一代際中從155MTr/mm²(百萬晶體管/平方毫米)階梯式提升至238MTr/mm²(晶體管密度計算公式爲:

麒麟SoC設計的面積利用率爲68%)——這種提升幅度,以往需要三年的幾何尺寸微縮才能實現。
SoC性能核心能效提升41%,最高主頻漲幅接近13%。
跨雙層搭建高速片上網絡數據通路,通路佔用面積縮減55%,供電穩定性同步改善。
硅後時鐘偏差優化方案獨立貢獻超 5% 的芯片整體性能增幅。
靜態隨機存儲器關鍵路徑縮短,單比特能耗降低,運行主頻提升超 40%,存儲讀寫速度、能耗與面積指標全面優化。
主流運算核心採用雙層摺疊架構,時鐘緩衝器數量減少超五成,時鐘偏差降低 25%,佈線長度縮減約 30%。
上述性能提升均在現有製程節點內完成,未採用全新光刻工藝,依靠三維空間重構邏輯電路佈局實現。
2026 款麒麟芯片搭載的邏輯摺疊技術採用保守落地方案:混合鍵合間距爲 1.5 微米,硅通孔接點僅相較頂層金屬層下移一層,摺疊技術僅針對性應用於核心關鍵路徑,未全芯片普及。即便如此,本年度 CPU 性能核心主頻仍回升至 3.1 吉赫茲。
未來十年,邏輯摺疊將從局部關鍵路徑摺疊,逐步升級爲全域多層摺疊,單封裝可堆疊三層、四層及更多有源芯片層。低溫混合鍵合技術可放寬多層散熱限制,硅通孔接點下移至第六金屬層,可釋放超三成高層佈線資源。
2026 至 2035 年,晶體管密度有望突破每平方毫米 4 億顆。邏輯摺疊技術將助力麒麟芯片大幅拉高 CPU 內核主頻,逐步邁向 4 吉赫茲及更高頻段。該技術路線落地可行,商業化成本具備經濟優勢。
混合鍵合間距:小於 2 微米,量產版 1.5 微米,目標間距比值 1:1
套刻精度:低於 0.5 微米
硅通孔規格:關鍵尺寸、隔離區小於 1.5 微米,間距小於 6 微米
良率:智能冗餘設計實現近乎滿良率
晶體管密度:單代漲幅 55%
性能核能效、主頻:分別提升 41%、13%
靜態存儲主頻:提升 40% 以上
核心單元損耗指標:時鐘緩衝器減半,偏差下降 25%,佈線縮短 30%
移動端低功耗場景驗證技術可行性後,該準則同樣適用於超高功耗人工智能訓練與推理場景。人工智能集群由成千上萬顆芯片協同運算,十年間整體算力規模提升六個數量級,全鏈路貫徹 τ 縮放思路,即可實現技術落地。
人工智能系統發展具備兩大特徵:芯片集群規模持續擴張;系統能耗與成本主要消耗於數據傳輸,而非運算處理。大型算力集群超八成能耗用於數據交互,七成以上成本投入存儲設備。由此可見,縮短芯片、機櫃、封裝內部的數據傳輸耗時,與優化運算耗時具備同等重要性。
AI 場景 τ 時間縮放依託三大協同架構落地:統一總線(Unified Bus)、封裝近距光互連引擎(Hi-ONE)、封裝拓撲重構三維摺疊(3D Folding)。
傳統多芯片加速系統層級協議繁雜,主機、機箱內部、機櫃之間採用不同通信協議,協議轉換、數據緩存、交互校驗不斷增加延遲,降低穩定性並推高成本。
統一總線架構摒棄多層協議體系,採用全域對等互聯協議,原生適配存儲訪問邏輯。數據傳輸無需協議轉換,依託硬件維護數據一致性,替代傳統軟件消息交互模式。實測遠程訪問延遲從數十微秒壓縮至 100 納秒,核心通信鏈路時間損耗縮減約 500 倍,大規模機櫃集群可實現一體化協同運行。
通信時延優化後,新瓶頸隨之顯現:單機櫃芯片密度提升導致功耗密度、可靠性觸達物理極限,傳統電互連 SerDes 帶寬也逼近上限。單 AI 芯片 400Gb/s 速率下,銅纜互連仍可靠可用;速率提升至 Tb/s 級後,銅纜方案徹底不可行:SerDes 傳輸距離驟降、佈線體積臃腫、機櫃安裝難度劇增,散熱與供電裕量耗盡。
華爲半導體提出高密度光互連節點引擎 Hi-ONE:封裝近距光互連模塊單路帶寬達 8Tb/s,與 AI 芯片統一總線帶寬精準匹配。技術收益:SerDes 傳輸距離從約 100 厘米壓縮至 5 厘米,摒棄笨重銅纜;跨機櫃傳輸距離從不足 1 米拓展至 100 米,爲吉瓦級超大規模數據中心高密度互連提供物理可行方案。
Hi-ONE 設計理念深度契合 τ 縮放思想:放棄高信號保真度專用數字信號處理器(DSP),採用模擬均衡增強驅動器 + 跨阻放大器線性架構;放寬比特誤碼率容忍度,由統一總線協議適配容錯機制。通過物理層與協議層跨層權衡,降低功耗、成本與集成複雜度,是 τ 理論跨層協同優化的典型實踐。
AI 加速器無法止步於 2.5D 扇出封裝,底層根源是幾何拓撲約束,直接決定 2030 年後技術路線。
傳統 2.5D AI 芯片架構:邏輯裸片居中,邊緣排布 HBM 存儲棧、SerDes 互連接口,外圍集成穩壓供電模塊。所有存儲信號、互連信號、供電電流都必須經過裸片邊緣才能接入內部計算單元。
設裸片邊長爲 N:
計算能力與芯片面積成正比,規模爲N²;
內存帶寬、互連帶寬、供電能力依託邊緣扇出,規模僅爲N。
二次增長的計算能力與線性增長的帶寬 / 供電能力差距持續拉大,形成扇出困局;即便邏輯工藝持續迭代,也無法彌補拓撲架構的先天短板,晶體管級優化無法解決架構層級的物理約束。
三維摺疊(3D Folding) 破解這一困局:將原本侷限於芯片邊緣的供電(背面供電 + 集成穩壓)、高速存儲(混合鍵合層疊集成)、光互連 I/O(Hi-ONE 近距集成)遷移至芯片垂直表面資源。資源佈局從邊緣環繞升級至全域立體分佈,帶寬、光互連、供電能力同步升級爲N²增長,與計算能力增速匹配。封裝形態徹底重構:從邏輯裸片 + 邊緣外設的平面結構,升級爲邏輯、互連、存儲、供電協同縮放的垂直集成棧。
AI 技術路線時間規劃
2030 年前:昇騰超集群(Ascend SuperPoD)依託芯粒、2.5D 扇出、微凸點 / 標準間距混合鍵合三維堆疊成熟技術迭代,代表產品 2025 昇騰 910C、2026 昇騰 950、後續昇騰 990;
2030 年左右:昇騰 990 首次將邏輯摺疊引入 AI 加速器;
2030-2035 年:三維摺疊成爲技術迭代核心載體,硬件集成度預計提升超 100 倍;τ 優化全面分佈於全棧各層級,不再侷限器件工藝層面。
統一總線遠程訪問時延:數十微秒→100 納秒,τ 縮減約 500 倍
Hi-ONE 單模塊帶寬:8Tb/s,匹配單芯片統一總線帶寬
Hi-ONE 傳輸距離:板內 SerDes 100cm→5cm;跨機櫃 1m→100m
扇出困局本質:計算能力 N² 增長,邊緣帶寬/I/O/供電僅N線性增長
三維摺疊價值:帶寬、光互連、供電從邊緣遷移至立體表面,恢復N²同步縮放
2026-2035展望:硬件集成度提升超100倍
τ縮放準則也推動邏輯芯片與存儲芯片產業格局變革。早期行業採用標準化總線,刻意區分處理器與存儲器,兩大產業各自獨立發展。
人工智能時代打破分離模式,算力暴漲不斷觸及存儲帶寬、延遲、封裝技術上限。高帶寬內存、混合鍵合、三維堆疊存儲技術,都印證數據傳輸與運算同等關鍵,邏輯與存儲芯片走向物理集成。產業話語權逐步向存儲、封裝企業傾斜。
技術融合已成必然趨勢,但產業利益分配模式尚未定型。未來硬件領域的優勝者,將實現邏輯與存儲技術深度整合,並構建長效共贏合作體系。τ縮放直觀體現分層分離帶來的損耗,倒逼產業儘快解決結構性融合問題。
τ縮放體系仍處於完善階段,多項關鍵難題有待攻克,同時也面向全行業尋求技術協作。
EDA工具鏈與設計方法論:現有EDA工具面向平面設計時代開發,面積、時序、功耗獨立優化,系統τ爲被動結果。全規模邏輯摺疊要求工具鏈將多層堆疊裸片視爲單一連續設計單元,支持單元級跨層劃分、全域統一成本函數佈局佈線、層間時序收斂;需兼顧垂直互連寄生參數、禁避區佔用、晶圓間工藝偏差等傳統二維工具無法適配的場景。華爲已自研初步工具鏈,方法論細節後續將公開發布;面向τ原生、多物理場、三維架構的開源EDA工具鏈,是未來十年最核心的基礎支撐投入。
晶圓間工藝偏差:邏輯摺疊可採用不同批次、甚至不同工藝節點晶圓鍵合堆疊。晶圓間閾值電壓、驅動電流、互連RC參數偏差遠大於單晶圓內部偏差,對時鐘分佈、保持時序裕量衝擊顯著。需依託智能冗餘、自適應補償、τ感知籤核流程建立完整解決方案。
垂直互聯損耗:混合鍵合、硅通孔(TSV)本身存在固有寄生電阻電容損耗,TSV禁避區會佔用標準單元佈局面積。邏輯摺疊落地需滿足核心判據:τ收益(有效芯片面積+佈線長度縮減)>τ損耗(垂直互連RC寄生)當前移動關鍵路徑、存儲場景已跨過收益閾值;閾值邊界隨鍵合間距縮小持續優化,且適配不同業務負載差異化判定標準。

能耗約束:τ是時間維度準則,而非能耗準則。架構提速10倍若伴隨功耗飆升10倍,雖不違背τ縮放原理,但會超出電網供電承載上限。因此τ縮放必須配套能耗優化體系:存儲語義總線消除協議棧開銷、封裝近距光互連將單比特能耗降低數個數量級、背面供電、存內/近存計算、數據中心級動態調頻調壓(DVFS);利用τ時序裕量反向換取功耗收益,實現時延與能耗雙向平衡。
基準測試體系:行業現有性能基準(Linpack、MLPerf、SPEC)面向單指標評估設計,無法適配τ縮放全棧優化需求。亟需構建τ剖面基準體系,量化系統各層級主導時延與優化裕量,精準定位下一階段核心投入層級。
2020年5月至2026年5月,華爲半導體面向移動、AI、汽車、工業、基礎設施領域,完成381款芯片量產落地,全產品矩陣驗證τ時間縮放理論成立:器件電路層面,預計2031年晶體管密度突破每平方毫米4億顆;芯片層面,固定制程下依靠邏輯摺疊持續提升主頻、能效與集成度;系統層面,通信延遲實現微秒到納秒級跨越,大型算力集群達成一體化協同;產業展望方面,2029年芯片主頻衝擊4吉赫茲,三至五年內移動端芯片能效翻倍,2035年人工智能硬件集成度增長百倍。
相較於產品迭代,τ縮放帶來的方法論革新意義更爲深遠。這是登納德定律之後,首個統一全計算架構優化目標的準則,讓工藝、電路、架構、軟件團隊圍繞同一指標協同升級。同時產業競爭邏輯轉變,不必單純追逐頂尖光刻製程,封裝、存儲帶寬、互聯架構成爲核心競爭力。
長期以摩爾尺寸縮減等同於技術進步的行業認知,迎來重大轉變。幾何縮放時代已然落幕,依託多層架構時間優化實現性能躍升成爲新方向。未來六至十年,以τ縮放爲核心發展目標的企業與生態,將主導下一代計算產業格局。
產業發展前路充滿挑戰,但演進方向清晰明確。各類技術難題無法依靠單一企業攻克,設計工具、行業標準、器件物理、商業模式均需全行業攜手共建。本文既是技術實踐總結,也誠摯邀請業界同仁共同探索前行。
風險及免責聲明:以上內容僅代表作者個人觀點,不代表富途任何立場,亦不構成任何投資建議,富途對此不作任何保證與承諾。更多信息
評論
發表評論