
CPU重返AI核心!誰是大贏家?
從數據、算力到應用的多層資本結構
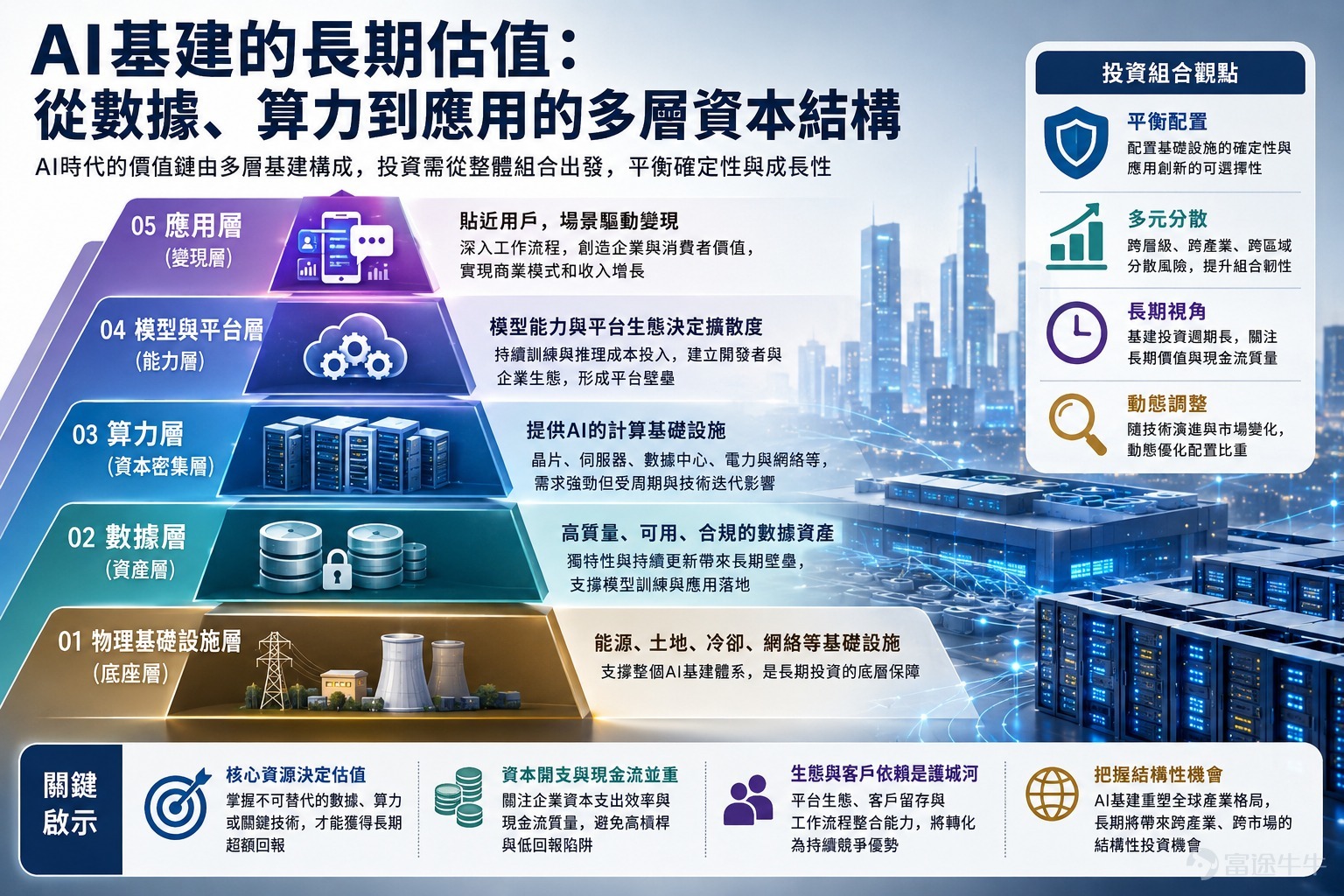
人工智能的投資熱潮,表面上看是模型能力的競賽,深層卻是一場基建資本的重估。過去市場習慣用互聯網平台的邏輯理解科技企業:誰掌握流量、誰能變現用戶,誰就擁有較高估值。但AI時代的價值鏈更複雜,它不只是一個應用故事,而是由數據、算力、模型、雲平台、能源、網絡與終端應用共同組成的多層資本結構。投資者若只追逐最耀眼的應用公司,容易忽略背後更長周期、更重資產、也更具定價權的基建環節。
首先,數據是AI基建中最容易被低估的一層。模型訓練依賴大量數據,但真正有價值的並非單純「量大」,而是數據的獨特性、準確性、可追溯性與合法使用權。公開數據會逐漸商品化,企業內部數據、專業行業數據、醫療金融法律等高質量資料,才可能形成持久壁壘。未來AI估值的核心問題之一,不是公司是否「用了AI」,而是它是否擁有可持續更新、可合規調用、可轉化為產品能力的數據資產。這使得部分傳統行業龍頭也有機會被重新定價,因為它們手中的數據沉澱,可能成為訓練垂直模型和提供智能服務的基礎。
其次,算力是AI資本開支最集中的環節,也是市場最容易形成泡沫與分歧的地方。晶片、伺服器、數據中心、散熱、電力供應和高速網絡,共同構成AI算力層。這一層的特點是需求確定性較強,但供給周期長、折舊速度快、技術替代風險高。投資者需要區分兩類企業:一類是具備核心技術與稀缺供應能力的上游公司,另一類是以高槓桿擴張算力資產、但議價能力有限的資本密集型公司。前者享受技術壁壘和供需緊張帶來的超額回報,後者則可能在供給過剩或租金下行時承受估值壓縮。
第三層是模型與平台。大型基礎模型看似最接近AI革命的中心,但其商業模式仍在演化。模型公司需要持續投入訓練與推理成本,還要面對開源模型追趕、雲平台綁定及價格競爭。長期來看,單一模型能力未必足以支撐永久高估值,真正重要的是模型能否成為開發者、生態夥伴和企業客戶依賴的平台。換言之,模型層的估值不應只看一次測試成績,而要看客戶留存、API調用規模、工具鏈整合、企業部署能力,以及是否能將技術優勢轉化為穩定現金流。
AI基建不是押注單一環節
最後才是應用層。這一層最接近用戶,也最容易產生爆發式增長,但競爭同樣最激烈。AI應用若只是把通用模型包裝成聊天介面,壁壘通常不足;若能深入工作流程,改變企業決策、軟件使用、內容生產或客戶服務方式,才有機會形成真正的商業價值。值得注意的是,AI應用的贏家未必全是新創公司。既有軟件企業若擁有客戶關係、分發渠道和行業場景,反而可能更快把AI功能轉化為收入。
因此,AI基建的長期估值應從整體投資組合出發,而不是押注單一環節。數據層提供長期壁壘,算力層承載資本周期,模型平台層決定技術擴散,應用層負責最終變現。不同層級的風險收益特徵並不相同:上游硬件可能受益於短期供需失衡,但周期性較強;數據和軟件平台增長較慢,卻可能有更高黏性;應用公司彈性最大,但失敗率也最高。成熟的AI投資組合,應同時配置「基礎設施的確定性」與「應用創新的可選擇性」。
(芯片與算力系列之55)

風險及免責聲明:以上內容僅代表作者個人觀點,不代表富途任何立場,亦不構成任何投資建議,富途對此不作任何保證與承諾。更多信息
評論
發表評論