國產算力,兵分三路對抗CUDA
導語:
英偉達的優勢從來不只是一塊 GPU,而是 CUDA 把芯片、編譯器、算子庫、框架接口和開發者習慣綁成了一整套體系。企業一旦在這套體系裏完成訓練、部署和運維,後續每一次遷移都會面對代碼重寫、算子補齊、框架重適配和性能回退的連鎖成本。
對國內廠商來說,這意味着兩個風險同時存在:一是長期依賴單一路徑,產業鏈的自主可控始終受限;二是即便硬件能替代,軟件生態也未必能跟上,結果是「有卡,但是難用」。這也是爲什麼國產算力討論到今天,問題已經從單點性能競爭,轉向生態組織能力的競爭。
一、智能體時代:FlagOS搭建國產芯片適配底座
先簡單科普下智源 FlagOS 。
作爲智源面向下一代 AI 基礎設施打造的全域智能操作系統,FlagOS 長期聚焦異構芯片適配、跨架構協同、AI 生態開放三大核心方向,核心目標是打破單一算力架構壁壘,爲大模型、AI 智能體、端邊側智能應用提供統一的底層運行底座。
隨着大模型進入智能體階段後。
模型不再只是做單輪生成,而是要跨框架、跨場景、跨設備持續運行,底層基礎設施就不能再只服務一種架構、一類任務。
衆智 FlagOS 2.0 給出的判斷很直接:如果沒有普適計算,智能體難以跨芯片運行;如果沒有開放計算,AI 生態就會被單一路徑鎖定。沿着這個邏輯看,國內產業對架構多元化和本土化替代的訴求,本質上都指向同一個問題——不是簡單複製一個 CUDA,而是先建立一套可以讓多種國產芯片共同接入、共同演進的公共底座。

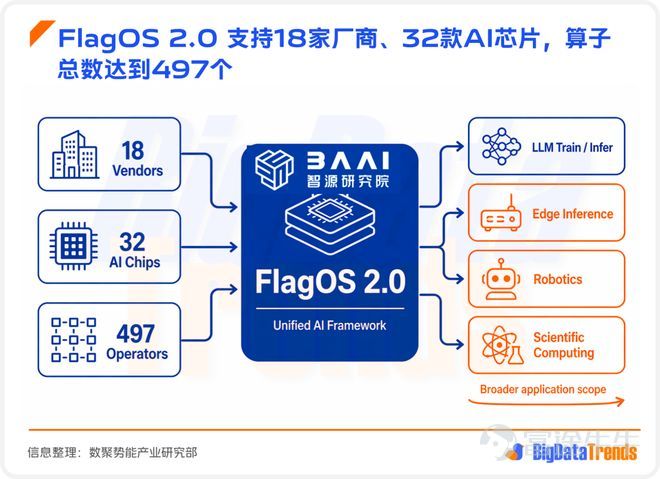
FlagOS 2.0 目前已支持18 家廠商、32 款 AI 芯片,算子總數達到 497 個,應用範圍也從大模型訓練推理擴展到邊緣推理、機器人和科學計算,這些數字的意義不在於規模更大,而在於它開始嘗試把分散的國產硬件,放進同一套軟件語言裏。
這也是海外封閉生態對國內創新真正的制約所在。
過去行業裏常見的做法,是每一種芯片配一套工具鏈、每一個框架做一次魔改、每一家廠商各自維護自己的適配版本。表面看,國內生態很熱鬧,但從開發者視角看,碎片化意味着學習成本和遷移成本持續累積。

FlagOS 2.0 在統一插件體系上連接vLLM、Megatron-LM、Transformer Engine等主流框架,在底層又通過Flag Tree、Flag Gems、FLIR這類組件推動編譯和算子層的統一,試圖解決的正是「一種芯片一套開發工具」的老問題。說得更直白一點,國內算力現在最缺的,是一套讓不同技術路線能共同參與競爭的基礎設施。

在這個背景下,智源推動的 FlagOS,更像是一場「先搭公共路基,再談單車速度」的嘗試。不是押注某一家芯片公司,而是把GPU、DSA、RPU(可重構數據流)三條路線同時納入同一套技術框架中。Triton-TLE 已支持 31 種原語,並分別在 GPU、DSA、可重構計算三類代表性架構上完成驗證;FLIR 也開始探索統一中間表示層,讓不同芯片共享一部分編譯優化能力。換句話說,智源並不是想證明哪條路線天然勝出,而是想先降低多路線並行的協同門檻。對一個仍在追趕期的產業來說,這比單點押注更現實。因爲國產生態的短板,從來不是沒有路線,而是路線太多但彼此不兼容。
二、除了打通芯片、模型與應用,也提供「第三種可能」
在芯片、模型和應用層,最核心的統一價值就是,對芯片廠商來說,減少重複適配和各自造輪子的成本;對模型廠商,它縮短從模型發佈到國產算力可用的時間差;對應用方,它至少提供了一種更可預期的遷移路徑,而不是每次換底座都從零開始。
FlagOS 2.0 裏FlagGems 已覆蓋 40 個主流模型、推理任務算子覆蓋度達到 90% 到 100%,FlagScale 則試圖把推理、訓練和強化學習的接入方式標準化。這些工作看上去偏底層,離市場很遠,但決定生態是否成立的,往往就是這些不顯眼的工程層。國內 AI 產業過去最容易掉進去的誤區,是把發佈當成落地;而統一適配標準,恰恰是把落地前面的摩擦一點點削掉。
GPGPU 仍然承擔通用計算主力,優勢是開發者熟悉、生態接口接近國際主流,DSA 代表更強的場景化優化能力,適合在既定任務模型下做深度打磨;而RPU(可重構數據流),提供的是第三種可能:它既不完全走 GPU 的通用堆疊,也不完全走固定數據流的專用設計,而是試圖在靈活性和效率之間找到一個新的平衡點。衆智 FlagOS 把它與 GPU、DSA 一起納入三條代表性架構路線,本身已經說明,可重構計算不再只是實驗室概念,而是被放進了國產生態的正式座標系中。
三、「第三種可能」:架構創新實現性能突破
RPU(可重構數據流)的差異化價值,核心在於通過「軟件定義硬件」核心技術,讓芯片硬件能根據不同AI任務實時動態重組,可兼顧高效性與靈活性,實現低延遲、低能耗,以此應對未來複雜多變的AI計算需求。
對行業來說,這件事的價值不只是一個性能數字,而是說明非 GPU 架構也有機會進入主流開發工作流,而不是永遠停留在能跑但難開發的階段。

從生態表現看,RPU 至少已經不再是邊緣角色。清微智能爲例,在 FlagOS 生態中的適配模塊數量位居前列,在非 GPU 架構中與華爲昇騰分列一二位,這意味着它在統一軟件棧裏的參與度已經進入第一梯隊。
更值得注意的是它的適配速度,尤其在最新模型適配上表現突出:4 月 8 日智譜 GLM-5.1 開源當天,清微智能即完成模型適配;在 4 月 24 日 DeepSeek 重磅發佈 V4 系列模型後,清微智能基於成熟的軟硬件協同架構,攜手智源衆智FlagOS,在模型發佈當天就完成了DeepSeek-V4-Flash版本的全量算子適配與驗證,成爲國內首批實現該模型全量算子兼容的芯片廠商。此外,清微智能還與千問等其他主流模型保持同步迭代,持續夯實其在國產AI算力生態中的核心地位。
四、演進:從分散替代到多架構組團協同
這也解釋了爲什麼國產架構競爭正在從分散替代走向組團協同。國內算力企業如果都試圖複製同一條路徑,結果很可能不是生態繁榮,而是同質化內耗:大家一起追一個最成熟、也最難追上的方向,最後誰都拿不到足夠大的開發者規模。
更合理的格局,是不同路線在各自擅長的場景裏補位:GPGPU 繼續承擔廣譜兼容任務,DSA 在高強度場景優化裏建立優勢,可重構架構則在模型快速適配、邊緣部署、輕量化推理和部分定製場景中釋放彈性。據了解,此前清微 RPU 與華爲昇騰形成的非 GPU 梯隊,至少已經讓這種互補關係具備了雛形。它不是誰替代誰,而是誰把國產架構的覆蓋面再往外推一步。
從這個角度看,未來,突破 CUDA 壁壘也許並不取決於是否有單點能力,能在所有維度上完全複製英偉達。更現實的路徑,是先建立一個能容納多種國產路線協同演進的生態,把工具鏈、算子、框架和模型適配變成公共能力,再由不同架構在不同場景裏分擔任務。FlagOS 的價值就在這裏:它讓國產芯片企業不必各自孤軍作戰,而是有機會在同一個生態裏共享一部分軟件資產、共享一部分開發者心智。對於還處在建設期的產業,這種組團價值,可能比單家廠商的短期性能衝刺更重要。
5、結語:架構多元化,引領國產AI生態發展
真正決定下一階段競爭的,也不會只是芯片參數,而是生態協同深度和技術落地能力。
架構多元化不是爲了證明哪條路線最正確,而是爲了讓國產 AI 不再被單一路徑定義。以 RPU 爲代表的創新架構,提供的不是對 GPU 的簡單跟隨,而是把國產算力從先適配、再優化的被動節奏,往按場景設計、按任務組織的主動節奏推了一把。
未來能否持續推進,關鍵不在於再講多少國產化替代敘事,而在於誰能把統一軟件棧做厚,把模型接入做快,把真實業務場景跑通,國產 AI 生態若想形成長效發展機制,最終比拼的不是某一家廠商講了什麼,而是誰真正把多架構協同這件事,做成了開發者願意用、客戶願意遷移的現實能力。
文章來源:數聚勢能
風險及免責聲明:以上內容僅代表作者個人觀點,不代表富途任何立場,亦不構成任何投資建議,富途對此不作任何保證與承諾。更多信息
評論
發表評論