Domestic computing power divides into three paths to counter CUDA
Introduction:
NVIDIA's advantage has never been just a single GPU but CUDA, which ties chips, compilers, operator libraries, framework interfaces, and developer habits into an entire system. Once enterprises complete training, deployment, and operations within this system, every subsequent migration will face the chain costs of code rewriting, operator supplementation, framework readaptation, and performance regression.
For domestic manufacturers, this means two risks exist simultaneously:One is the long-term reliance on a single path, with the autonomy and control of the industrial chain always limited; the other is that even if hardware can be replaced, the software ecosystem may not keep up, resulting in 'having the card, but it's difficult to use.'This is also why the discussion on domestic computing power has shifted from competition in single-point performance to competition in ecosystem organization capabilities.
I. The Age of Intelligent Agents: FlagOS Builds a Domestic Chip Adaptation Base
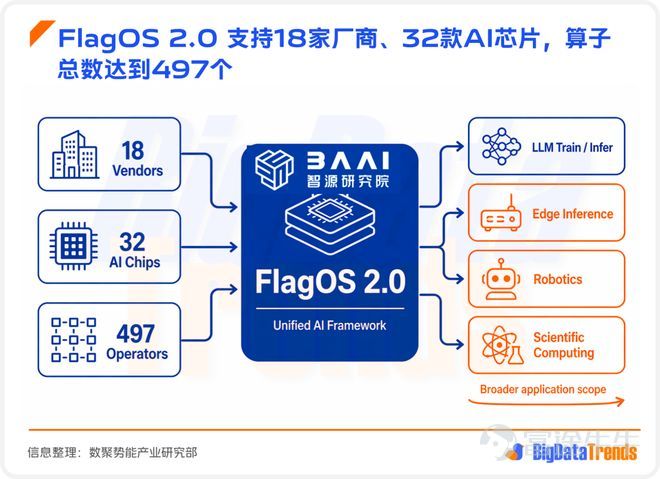
Let’s briefly introduce Zhiyuan FlagOS.
As Zhiyuan's next-generation AI infrastructure-focused universal intelligent operating system, FlagOS has long focused on three core directions: heterogeneous chip adaptation, cross-architecture collaboration, and AI ecosystem openness. Its core goal is to break the barriers of a single computing architecture and provide a unified underlying operational base for large models, AI agents, and intelligent applications on the device edge side.
With large models entering the agent stage.
Models are no longer limited to single-round generation but need to operate continuously across frameworks, scenarios, and devices. Therefore, the underlying infrastructure can no longer serve just one architecture or type of task.
The judgment given by FlagOS 2.0 is straightforward: without universal computing, agents will struggle to run across different chips; without open computing, the AI ecosystem risks being locked into a singular path. Following this logic, domestic industries’ demand for architectural diversity and localized substitution essentially point to the same issue — it’s not about simply replicating something like CUDA, but rather establishing a shared foundation that allows various domestic chips to connect and evolve together.

FlagOS 2.0 currently supports18 manufacturers and 32 AI chips, with a total number of operators reaching 497, and its application scope has expanded from large model training and inference to edge inference, robotics, and scientific computing. The significance of these numbers lies not in their scale, but in startingto bring fragmented domestic hardware under one unified software language.
This is also where overseas closed ecosystems truly constrain domestic innovation.
A common practice in the industry in the past wasto pair each chip with its own toolchain, heavily modify every framework, and let each manufacturer maintain its own adaptation version.On the surface, the domestic ecosystem seemed vibrant, but from a developer’s perspective,Fragmentation means the continuous accumulation of learning and migration costs.

FlagOS 2.0 connects through a unified plugin systemvLLM, Megatron-LM, Transformer Engineand other mainstream frameworks, while at the lower level it uses components likeFlag Tree, Flag Gems, FLIRto drive unification at the compilation and operator levels, aiming to solve the longstanding issue of 'one set of development tools for each type of chip.' To put it more bluntly, what domestic computing power lacks most right now is infrastructure that allows different technical routes to compete together.

In this context, the FlagOS promoted by Zhiyuan resembles an attempt to 'build a common roadbed first before discussing single-vehicle speed.' It doesn't bet on one chip company but integratesGPU, DSA, RPU (Reconfigurable Dataflow) into the same technical framework simultaneously.Triton-TLE already supports 31 primitives and has completed validation on three representative architectures: GPU, DSA, and reconfigurable computing; FLIR has also begun exploring a unified intermediate representation layer, enabling different chips to share some compilation optimization capabilities. In other words, Zhiyuan isn't trying to prove which route naturally prevails but rather aims to first lower the coordination threshold for multiple parallel routes. For an industry still in its catch-up phase, this is more realistic than betting on a single point because the weakness of the domestic ecosystem has never been about the lack of routes but rather too many routes that aren't compatible with each other.
Second, in addition to connecting chips, models, and applications, it also provides a 'third possibility.'
At the chip, model, and application layers, the most fundamental unified value is that for chip manufacturers, it reduces the cost of redundant adaptations and reinventing the wheel; for model developers, it shortens the time gap between model release and availability on domestic computing power; for application users, it provides at least a more predictable migration path, rather than starting from scratch every time the underlying infrastructure changes.
In FlagOS 2.0, FlagGems already covers 40 mainstream models with operator coverage for inference tasks reaching 90% to 100%, while FlagScale aims to standardize the integration methods for inference, training, and reinforcement learning. These efforts may seem low-level and distant from the market, but what often determines whether an ecosystem can succeed are precisely these unassuming engineering layers.The biggest misconception in China's AI industry in the past has been treating announcements as real-world implementations; whereas establishing unified adaptation standards gradually eliminates the friction leading up to implementation.
GPGPUs still serve as the mainstay for general-purpose computing, offering the advantage of developer familiarity and ecosystem interfaces close to international standards, while DSAs represent stronger scenario-specific optimization capabilities, making them suitable for deep refinement under predefined task models.RPU (Reconfigurable Dataflow) offers a third possibility: it neither fully adheres to the generalized stacking of GPUs nor completely follows fixed data flow designs, but instead seeks to strike a new balance between flexibility and efficiency.FlagOS incorporates it alongside GPUs and DSAs as one of three representative architectural approaches, indicating that reconfigurable computing is no longer just a laboratory concept but has been formally integrated into the domestic ecosystem.
Section Three: 'The Third Possibility' - Achieving Performance Breakthroughs through Architectural Innovation
RPU (Reconfigurable Dataflow)Its differentiated value lies in its core technology of 'software-defined hardware,' allowing chip hardware to dynamically reconfigure in real-time based on different AI tasks, balancing efficiency with flexibility, achieving low latency and low energy consumption, thus addressing the complex and evolving demands of future AI computing.
For the industry, the significance of this development goes beyond mere performance figures; it shows that non-GPU architectures also have the opportunity to enter mainstream development workflows, moving beyond the stage of being functional but difficult to develop.

In terms of ecosystem performance, RPU is at least no longer a marginal player. Taking ClearMicro Intelligence as an example, the number of adaptation modules within the FlagOS ecosystem ranks among the top, and in non-GPU architectures, it stands alongside Huawei Ascend as one of the top two performers. This indicates that its participation in the unified software stack has entered the first tier.
More notably, its adaptation speed stands out, especially in the case of the latest model adaptations: On April 8, the day Zhipu GLM-5.1 was open-sourced, ClearMicro Intelligence completed the model adaptation; on April 24, following the significant release of DeepSeek's V4 series models, ClearMicro Intelligence, leveraging its mature hardware-software co-design architecture, collaborated with BAAI’s FlagOS to complete full operator adaptation and verification for the DeepSeek-V4-Flash version on the same day, becoming one of the first domestic chip manufacturers to achieve full operator compatibility for this model. In addition, ClearMicro Intelligence remains in sync with other mainstream models such as Qwen, continuously strengthening its core position in the domestic AI computing power ecosystem.
IV. Evolution: From Fragmented Substitution to Multi-Architecture Synergistic Collaboration
This also explains why domestic architecture competition is transitioning from fragmented substitution to collaborative group efforts. If all domestic computing power companies attempt to replicate the same path, the result may not be ecosystem prosperity but rather homogenized internal friction:Everyone chasing after the most mature, yet hardest-to-catch-up direction will ultimately leave no one with a sufficiently large developer base.
A more reasonable structure would involve different approaches complementing each other in their respective areas of expertise: GPGPU continues to handle broad compatibility tasks, DSA builds advantages in high-intensity scenario optimization, and reconfigurable architectures demonstrate flexibility in rapid model adaptation, edge deployment, lightweight inference, and some customized scenarios. It is understood that the non-GPU lineup formed by ClearMicro RPU and Huawei Ascend has already provided a prototype for this complementary relationship. It is not about who replaces whom, but about who pushes the coverage of domestic architectures further outward.
From this perspective, breaking through the CUDA barrier in the future may not depend on whether there is single-point capability that can fully replicate NVIDIA across all dimensions. A more realistic pathis to first build an ecosystem capable of accommodating multiple domestic routes evolving collaboratively, turning toolchains, operators, frameworks, and model adaptation into shared capabilities, then allowing different architectures to take on tasks in different scenarios. The value of FlagOS lies here: it allows domestic chip companies to avoid fighting alone, offering them the opportunity to share part of the software assets and developer mindshare within the same ecosystem. For an industry still in its construction phase, this collective value may outweigh the short-term performance sprints of individual manufacturers.
V. Conclusion: Architectural diversification leading the development of the domestic AI ecosystem
What truly determines the next phase of competition is not just chip parameters, but the depth of ecosystem collaboration and the ability to implement technology.
The diversification of architectures is not about proving which path is the most correct, but about ensuring domestic AI is no longer defined by a single approach. Innovative architectures represented by RPU do not simply follow GPUs but push domestic computing power fromFirst adapt, then optimizea passive rhythm towardsdesigning for scenarios and organizing by tasksan active rhythm.
The key to whether progress can be continuously made in the future does not lie in how many more narratives of domestic substitution are told, but rather in who can build a robust unified software stack, quickly connect models, and successfully run real business scenarios. For the domestic AI ecosystem to form a long-term development mechanism, the ultimate competition will not be about what one vendor says, but about whocan truly turn multi-architecture collaboration into a practical capability that developers are willing to use and clients are willing to migrate to.
Source: Data Momentum
Risk Disclaimer: The above content only represents the author's view. It does not represent any position or investment advice of Futu. Futu makes no representation or warranty.Read more
Comments
to post a comment