
美光市值破1萬億,存儲「週期魔咒」被顛覆?
谷歌TurboQuant引發存儲巨震!一文深度拆解:這是黃金坑還是真利空?
論文披露了一項名為TurboQuant的超高效AI內存壓縮算法,在硅谷科技圈引起轟動。谷歌宣稱,該算法能夠在零精度損失的前提下,將大語言模型運行時的緩存消耗銳減至少6倍,同時實現高達8倍的性能飆升。簡而言之,這項技術讓AI能夠以更小的內存代價,記住并處理更海量的信息。

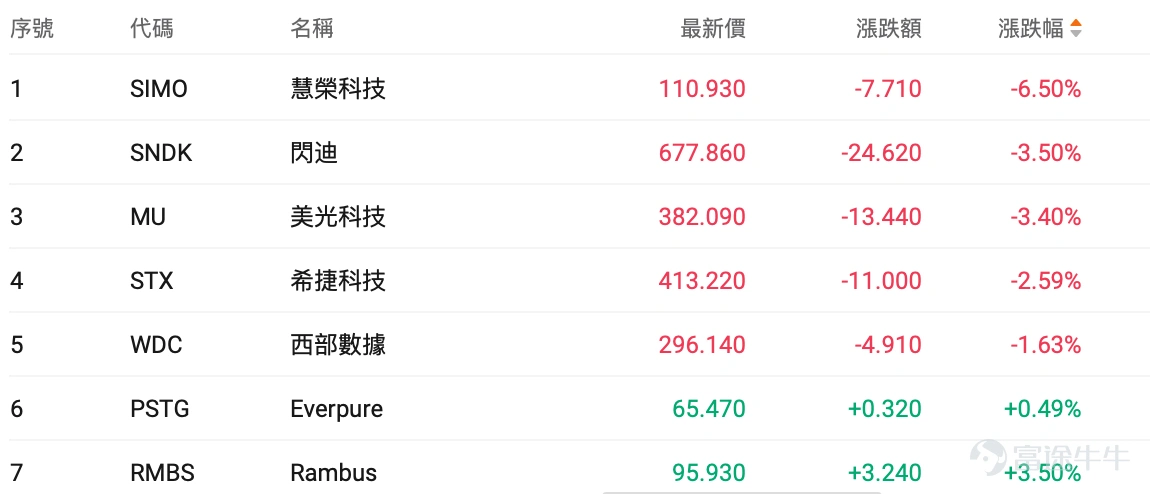
受此消息發佈,隔夜 $閃迪 (SNDK.US)$ 、 $美光科技 (MU.US)$ 跌逾3%, $希捷科技 (STX.US)$ 跌逾2%, $西部數據 (WDC.US)$ 跌逾1%。今日,港股 $南方兩倍做多海力士 (07709.HK)$ 跌逾12%, $南方兩倍做多三星電子 (07747.HK)$ 跌逾10%。
這一算法一經發布,在華爾街也掀起了一場熱烈討論:當前困擾眾多科技巨頭的內存芯片短缺災難是否可以就此終結了?本文將帶牛友們了解什麼是TurboQuant,以及對行業的影響。
TurboQuant是什麼?
先來說說這項TurboQuant算法具體是什么。根據谷歌在官方網站的介紹,TurboQuant是一種壓縮方法,它能夠在不損失任何精度的前提下大幅減小模型大小,因此非常適合支持鍵值緩存(KV Cache)壓縮和向量搜索。它通過兩個關鍵步驟實現這一點:
1、高質量壓縮:TurboQuant 首先隨機旋轉數據向量。這一巧妙的步驟簡化了數據的幾何結構,使得可以輕松地將標準的高質量量化器分別應用于向量的每個部分。第一階段利用了大部分壓縮能力(大部分比特)來保留原始向量的主要概念和特征。
2、消除隱藏誤差:TurboQuant 使用少量剩余的壓縮能力(僅1比特)將QJL算法應用于第一階段遺留的微小誤差。QJL 階段充當數學誤差檢查器,消除偏差,從而獲得更準確的注意力評分。
💡看到這里,相信不少投資者還是一頭霧水。那麼簡單來說,AI在回答你長篇大論的問題(推理)時,腦子往往記不住前面說過的話,所以需要一邊看一邊瘋狂「打草稿」,這個臨時草稿本極其占地方。TurboQuant就是谷歌發明的一套「神仙級草稿本壓縮術」。
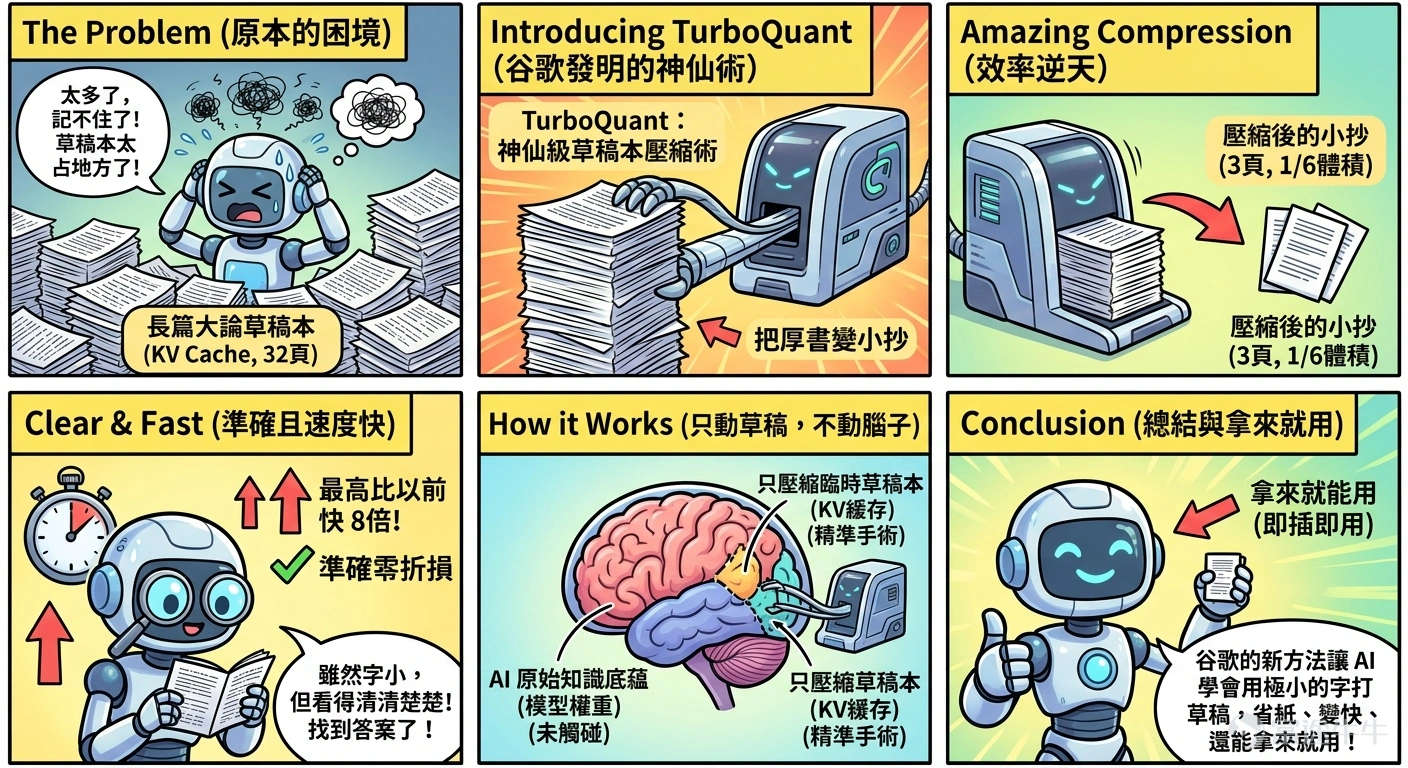
效率逆天(把厚書變小抄):以前AI記一個知識點需要用32頁紙,現在用了這套技術,只需要3頁紙就能搞定,硬生生把草稿本變薄了6倍。最牛的是,就算字被縮得這么小,AI依然能看得清清楚楚,一道題都不會答錯(準確率零折損)。而且,AI翻看這個「小抄」找答案的速度,最高竟然還能比以前快8倍!
只動草稿,不動腦子(精準手術):這項技術非常「懂事」,它只負責壓縮那個你聊天越長、它就越厚的「臨時草稿本」(專業叫法是KV緩存)。它絕對不去亂碰AI原本儲存在腦子里的知識底蘊(模型權重),也不會干擾AI最初的學習過程(訓練)。
拿來就能用(零門檻):最好的一點是,你不需要把AI送回學校重新培訓,教它怎么使用這個新草稿本。它就像買了個新手機殼一樣,套上去直接就能用(即插即用),極其省事。
用一句大白話總結就是:谷歌發明了一種新方法,讓AI突然學會了用極小的字打草稿,不僅省下了一大半紙,做題速度還變快了,而且拿來就能用。
破除迷思:硬件需求真的會暴跌嗎?
針對市場的恐慌,摩根士丹利給出了明確的定調:這并不是對存儲或總體硬件需求的6倍削減,而是單個GPU吞吐量的大幅提升。
杰文斯悖論效應:報告指出,長遠來看,效率的提升往往會刺激總需求的增長。
從「省錢」到「花在刀刃上」:雲服務巨頭極有可能將這些效率紅利重新投資于,運行更大的模型/更長的上下文窗口、處理更高的查詢量,以及改善延遲服務等級協議(SLA)。
結論:這意味著效率提升將激活更多原本受制于成本而無法落地的AI應用場景。該技術重塑了AI部署的成本曲線,對算力與內存硬件的長期影響不僅不是利空,反而呈現出「中性偏正面」的積極信號。
市場影響深度拆解:行業贏家與輸家
摩根士丹利認為,TurboQuant的出現堪稱「又一個DeepSeek時刻」,正在重塑AI部署的成本曲線。
1. 最大贏家 - 雲服務巨頭與大模型平臺
這個陣營是技術紅利的第一受益者,推理成本的斷崖式下降將直接轉化為利潤率的提升。
$微軟 (MSFT.US)$ & $亞馬遜 (AMZN.US)$ : 全球最大的雲端基礎設施提供商(Azure, AWS)。大模型推理成本降低,意味著它們能以相同的算力集群服務更多客戶,獲取更高的雲端租賃 ROI。
2. 新增長極 - 邊緣計算與終端 AI
這是過去受制於「內存瓶頸」,導致大模型難以完美落地的板塊。TurboQuant 讓模型變「輕」,將極大刺激端側設備的爆發。
$高通 (QCOM.US)$ & $Arm Holdings (ARM.US)$ : 終端設備(手機、AI PC)算力架構和芯片的核心供應商。當 AI 能在本地低功耗流暢運行,將直接引爆 AI PC 和 AI 手機的換機潮。
3. 硬件與內存廠商 (短期中性,長期利好)
雖然市場第一時間恐慌性拋售,但「傑文斯悖論」預示著效率提升會引爆總需求。
算力核心: $英偉達 (NVDA.US)$ / $美國超微公司 (AMD.US)$ ,TurboQuant 在 NVIDIA H100 GPU 上實現了高達 8 倍的速度提升。效率紅利會被雲廠商重新投資於更大的模型和更長的上下文,GPU 總體需求不會被削弱。
存儲巨頭: $美光科技 (MU.US)$ / $南方兩倍做多海力士 (07709.HK)$ / $南方兩倍做多三星電子 (07747.HK)$ ,AI 基礎設施供應鏈中的內存核心。雖然短期內單個任務的內存佔用減少,但長期來看,AI 應用的全面普及和更大規模的並發處理,將持續帶動 HBM(高帶寬內存)和高密度 DRAM 的基本面。
4. 潛在受損者 - 軟件中間層
這個板塊主要集中在一些提供 MLOps(機器學習運營)和 AI 基礎設施優化的公司。
數據庫服務商 :$Snowflake (SNOW.US)$ ,因為這種底層壓縮技術可以直接嵌入到平台基礎設施中。這意味著,過去那些單純依靠提供「模型壓縮」、「推理加速」或「外掛緩存優化」來賺取差價的第三方軟件公司,其技術壁壘和定價權可能會被雲巨頭免費集成的底層技術所擠壓。
總結
總結而言,TurboQuant並非證偽AI硬體景氣度,而是大幅降低推理成本,加速應用落地。短期技術突破雖引發存儲板塊估值擾動,但基於「傑文斯悖論」,效率的極致提升終將催生更龐大的總體算力與內存需求。
風險及免責聲明:以上內容僅代表作者個人觀點,不代表富途任何立場,亦不構成任何投資建議,富途對此不作任何保證與承諾。更多信息





評論(52)
發表評論
174
1201